

-

-
第3章 显著性检验
来源:默认管理员点击数:587发布时间:2012-12-18本章主要内容:
l认识统计显著性的实质
l理解假设建立的概念及如何检验假设
l 理解第一类误差和第二类误差的区别
l 描述几种常见的统计检验方法
l方差分析
3.1 评估差分和变化
测量方法是否有区别是营销管理人员关心的众多问题的核心。下面是几个具体例子:
l 我们对认知度所做的事后测试的结果高于事先测试的记录。是认知度真的提高了,还是另有别的解释?我们是该终止与代理商的关系还是继续委托它?
l 我们的整体顾客满意度得分从3个月前的92%上升到今天的93.5%,顾客满意度真的提高了吗?我们是否应该庆祝一番?
l 采用10点制量表,达拉斯顾客对我们的有线电视系统提供的客户满意程度比辛辛那提的平均要高1.2。达拉斯的顾客顾客真的更为满意么?辛辛那提的顾客服务负责人员是否该被撤换?达拉斯的负责人是否该受到奖励?
l 在最近的一次产品创意调查中,19.8%的被调查者说他们非常可能购买他们评估的新产品。这是否是好事?是否比我们去年对类似产品所做的调查结果要好?这种结果对我们是否推出新产品的决策有何意义?
l 在一项市场细分调查中,我们发现年收入30000美圆以上的人去快餐店的次数平均每月为6.2次,而年收入为30000美元或以下的人去的次数为6.7次,这种差别是否真实?是否有意义?
l 在一项认知度调查中,28.3%的被调查者在无提示的情况下说知道我们的产品。这是一个好的结果么?
以上这些是在营销调研中永远存在的问题。尽管被一些人认为枯燥,但它们却正是统计假设检验为什么重要的原因。假设检验有助于更接近这些问题的最终答案。我们说接近,是因为在市场调研中很少能完全确定地回答这些问题。
3.2 统计显著性
统计推断最根本的目的是从抽样调查的结果中归纳出总体的特征。统计推断的基本信条是,在数学意义上不同的数字在统计学意义上可能并没有显著的不同。例如,调查人员要求喝可乐的人蒙上眼睛品尝两种不同的可乐并说出自己更喜欢哪一种。结果表明,51%的人倾向于被试验的一种,49%的人倾向于另一种。这里有一个数学上的差别,但这种差别极小且并不重要。它可能在我们准确判断自己口味偏好能力的误差范围之内,这种差别在统计意义上可能并不显著。关于差分有三个不同的概念:
l 数学差分 根据定义,如果几个数字不完全相同,它们就有差分。然而,这并不能说明差分的重要性及在统计上的显著性。
l 统计显著性 如果一个特殊的差分大到不可能是由于偶然因素或抽样误差引起的地步,那么这个差分在统计意义上是显著的
l 管理意义上的重要差分 如如果或数字的差异程度从管理角度看是有意义的,那么我们可以说这个差分是重要的。例如,在顾客对两种不同包装的反应的调查中,其差分在统计上也许很显著,但可能小到没有实际及管理上的重要性。
在本章,我们将介绍几种检验结果是否具有统计显著性的方法。
3.3 假设检验
假设可以定义为一个管理者或管理者对被调查者总体特征所做的一种假定或猜想。营销人员常常要面临这样的问题,即调查结果是否与标准有很大的差别,以便决定公司营销策略的某些方面是否需要改变。让我们看看下面几种情形:
l 一项跟踪调查的结果表明,顾客对产品的了解程度比6个月前所做的类似调查中显示的要低。结果是否明显降低?是否低到需要改变广告策略的程度?
l 一位经理认为其产品购买者平均年龄为35岁。为检验其假设,他进行了一项调查,调查表明购买者平均年龄为36.5岁。调查结果与其观点的差别是否足以说明此经理的观点是不正确的?
l 一家快餐店的营销部长认为她的顾客中60%为女性,40%为男性。为此她进行了一项调查,通过调查她发现顾客55%为女性,45%为男性。调查结果与她原来假设的差别是否足以让她得出“她原来的假设是错误的”这一结论?
所有这些问题都可以通过一定的统计检验来评估。在假设检验中,调查者测定一个关于总体特征的假设是否有根据。如果假设确实正确,统计假设检验便可以让我们计算出一个特殊结果的概率。
对于一项具体调查结果与假设值之间的差分有两种主要的解释:假设是正确的,差分很可能是因为抽样的错误造成的;或者假设很可能是错误的,真正的数值是另外的值。
假设检验的步骤
检验一个假设主要有五个步骤。首先必须被明确。其次,选择适当的统计方法来检验假设。第三,判断标准必须明确,并作为决定是否拒绝或不能拒绝(FTR)原假设H0的基础。请注意,我们不说“拒绝H0或接受H0”,尽管这看似很细微的区别,但却很重要。对这一区别我们在后文中进一步论述。第四,计算检验统计值并进行检验。第五,从初始问题或调查问题的角度陈述结论。
1 陈述假设
假设主要用两种形式:原假设H0与备择假设H1,原假设H0与备择假设H1在检验时是相对的。例如:调研部经理认为他的操作程序将使顾客在汽车购物窗前的等待时间为2分钟,1000个样本的平均时间为2.4分钟,这时,原假设与备择假设将表示如下:
原假设H0:标准等待时间=2分钟
备择假设H1:标准等待时间¹2分钟
2 选择适当的检验统计量
本章将介绍几种检验方法,分析人员必须根据调查情况选择合适的统计检验方法。
3 确定判定规则
从前面关于样本均值的讨论中可以发现,抽样结果与总体参数完全相等的情况几乎是不可能发生的。关键的问题是,如果统计假设是正确的,实际样本平均数和假设平均数间的差分是否会在一个可以接受的范围。因此,需要一个判断规则或标准,来决定是否拒绝或不拒绝原假设。统计上用显著水平来说明判定规则。
显著水平(a)在选择原假设和备择假设的过程中是很关键的。显著水平是判定原假设的可接受性时的一种认为很低的概率,如0.10,0.05或0.01。
如果我们决定一项显著水平为0.05的假设,这表示如果由于巧合或抽样误差,检验表明观察结果发生的概率为5%,那么我们将拒绝原假设。对原假设的拒绝相等于认同备择假设。
4 计算统计检验值
在这一步骤中,要求:
l 运用适当的公式计算统计检验值
l 比较计算值与根据判定规则所得的严格的统计值(从适当的统计表格中查得)
l通过比较,得出是否拒绝原假设H0的结论
5 表述结果
从初始研究问题的角度表述你的结论,以总结检验结果。
3.4 假设检验中的两类错误
假设检验中容易犯两种错误类型,一般称之为第一类错误和第二类错误。第一类错误发生在如下情形:调查者拒绝了原假设,而实际上它是正确的。调查得出的这种不正确的结论也许是由于样本与总体值的差分是由于抽样误差造成的。调查者必须决定在多大程度上认同第一类错误。认同第一类错误的可能性被认为是a水平。相反地,如果在它事实上正确的时候,我们没有拒绝它,那么1-a将是得出正确结论的概率。
第二类错误发生在如下情形:原假设错误,而调查者没有拒绝它。第二类错误被认为是b错误,1-b的值,反映了在原假设错误的时候,作出正确决定拒绝它的概率。这些不同的概率总结于表3.1中
表3.1 第一类错误和第二类错误
.jpg)
然而,对b的估计更为复杂,且已超出我们讨论的范围。并且,第一类错误与第二类错误并不是互补的,即
.jpg)
对于任何假设检验,我们都希望能控制n(样本容量)、a(第一类错误)及b(第二类错误)。遗憾的是,这三个量中我们只能控制两个。对于一个规定了样本量的问题,n是固定的,因此,a与b只能控制一个。
3.5 假设检验方法
本章将介绍最常用的
.jpg) 检验和t检验
检验和t检验3.5.1 t检验
(1) t分布的背景
从均数为m、标准差为s的正态分布总体中,随机抽取一个含量为n的样本,样本均数为
.jpg) ,
,理论证明:
服从均数为.jpg) 、标准差为
、标准差为.jpg) 的正态分布,对其进行标准化,表达式
的正态分布,对其进行标准化,表达式.jpg) 的正态分布,对其进行标准化服从标准正态分布,由于s未知,用样本标准差S代替,表达式,表达式
的正态分布,对其进行标准化服从标准正态分布,由于s未知,用样本标准差S代替,表达式,表达式.jpg) 所服从的分布即为t分布。
所服从的分布即为t分布。(2) t分布的特点
t分布类似于标准正态分布,以0为中心,左右两侧对称,中间面积大,两侧面积小,象一个‘钟型’曲线,曲线下的面积为1,理论证明,当样本含量趋向无穷时,t分布即为标准正态分布。
对任意给定的概率a,总对应一个点,在这个点的左侧的面积为a/2,这个点,在统计学上称为界点,常用
.jpg) 表示,即从
表示,即从.jpg) 至,包含了总体1-a的个体,a常取值0.05、0.01。
至,包含了总体1-a的个体,a常取值0.05、0.01。(3) t检验的基本思想
有一个服从正态分布的总体,研究者想知道总体均数是否为m0,于是从中随机抽取一个样本,若总体均数为m0,不妨取a=0.05,则
.jpg) 服从t分布,t值应位于
服从t分布,t值应位于.jpg) ,否则,有理由怀疑总体均数为
,否则,有理由怀疑总体均数为.jpg) 。
。(4) t检验的基本步骤
第一步 建立假设并确定检验水准
假设有两种:1)检验假设H0(hypothesis to be tested)
.jpg)
2)备择假设H1(alternative hypothesis)
.jpg)
常取a=0.05或a=0.01
第二步 选定统计方法,计算统计量
.jpg)
第三步 确定P值和作出推断结论
如
.jpg) ,则
,则.jpg)
,认为H0不成立,否则,不拒绝H0。
(5)实例
某媒体报道:2000年广州居民家庭平均总收入为3.6万元,报道是否正确?某调查公司随机调查了20个家庭,数据如下(单位:万元):2.3、3.8、4.5、3.3、3.5、5.6、4.3、6.2、2.8、5.2、3.2、3.8、4.8、3.2、3.9、4.6、4.5、5.2、3.8、5.5
经计算: ,S=1.02,n=20
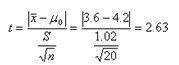
查t界值表t0.05(20-1)=2.093,t>t0.05(20-1),P<0.05,可以认为,广州市居民的年平均总收入不是3.6万元。
(6) t检验的基本类型
t检验常用于以下3种情况
(a) 样本均数与总体均数比较的t检验
(b) 两样本均数比较的t检验
检验假设
.jpg) ,备择假设
,备择假设.jpg)
统计量为:
.jpg)
自由度n=n1+n2-2
其中,
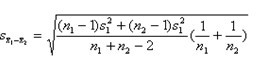
(c) 配对设计的t检验
3.5.2
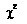 检验
检验基本思想
举例说明,调研部经理对广州、北京两城市居民进行了电话访问,样本量分别为110、105。广州100名被访者中,60名使用该公司洗头水,40名使用其他厂家产品;北京100被访者总52名使用公司洗发水,48名使用其他厂家产品,调研部经理需要判断,该公司在两城市的洗发水市场的占有率是否相同。现将资料整理成如下形式:
表3.2 甲、乙两地某品牌洗发水使用情况

表中,A11、A12、A21、A22这四个格子的数据是整个表的基本数据,其余数据都是从这四个基本数据推算而来,因而,称该表为四格表。我们想了解,广州、北京该公司的占有率是否相同?经计算,广州样本率为P1=59.1%;北京为P2=46.7%,广州、北京两地的样本率不同,这个不同是由两地总体率不同造成的?还是仅由抽样误差造成的?下面进行假设检验
检验步骤为:
.jpg) ,即两地该公司占有率相同
,即两地该公司占有率相同.jpg) ,即两地占有率不相同
,即两地占有率不相同显著水平a取0.05,由相应表格查得,
.jpg) 界值为3.84
界值为3.84统计方法,选用
检验,公式为: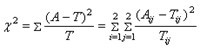
其中Aij为实际数,Tij为理论数,计算公式为
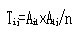
本例计算如下:T11=121x110/215=61.9,同理可计算T12=110-61.5=48.1,T21=59.1,T22=45.9,代入公式,可得:
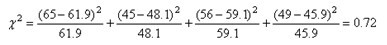
由相应表格查得,a=0.05时
界值为3.84,由此可得出P<0.05
结论:P1与P2的差分按0.05的显著水平属于抽样误差,不拒绝H0,认为该公司在广州、北京的占有率相同。
3.6 方差分析
方差分析(Analysis of Variance,简称ANOVA)是一种对多个样本均数进行分析比较的统计方法,其基本原理是:指标的总变异又类别间的变异与随机变异组成,通过分析总变异的构成,推断各类别总体均数是否相同。
若需要检验两个或两个以上独立样本平均数的差异,方差分析(ANOVA)是一种合适的统计工具。虽然它可以用来检验两个平均数的差异,但是它更主要地是用于对3个或3个以上独立群体的平均数差异的假设检验。可以用方差分析确定样本之间平均数的差异是否由抽样误差而引致的。上面论及的t检验可用于只涉及两个样本平均数时的检验假设,当有3个或3个以上样本时,利用这两种方法缺乏效率。例如,如有5个样本及相应的平均,那么就需10次t检验来检测每一对平均数。值得注意的是,当有3个或更多个平均数出现时,使用Z检验或t检验,也增加了出现每类错误的可能性。每两个不同平均数的组合都必须被检验。检验的次数越多,夸大一对(或更多对)平均数真正由于抽样误差引起显著差异的机会就越大。若显著性水平为0.05,平均在20次检验中就会出现一次。
单向方差分析经常被用来分析实验结果。例如,一家汽车配件连锁店的市场总经理正在考虑采用三种可能的服务来促销:车轮校正、换油、调试。她想知道这三种方法带来的潜在销售量是存在显著差异。
在3个城市中共随机出60家连锁店(每个城市选 20家),每个城市分别增加一项服务,实验期间的价格和广告等保持一致。实验共进行30天,其间的销售情况将逐一记录。
表15-6快步示了每家店的平均销售额。问题是,引起这些差异的主要原因是促销方式还是纯属偶然?
3.6.1 基本统计指标
(1) 总变异
统计量是总的离均差平方和,用SS总表示,假定共有k个类别,每类分别有ni(i=1,2,…,k)个个体,公式为:
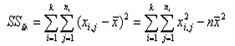
其中,
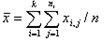 ,自由度
,自由度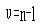
(2) 组间变异
组间变异为:
.jpg)
组间均方变异为:
.jpg)
其中,
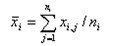 (i=1,2,…,k) ,自由度
(i=1,2,…,k) ,自由度.jpg)
(3) 组内变异
组内变异为:
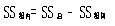
组间均方变异为:
.jpg)
其中,自由度
.jpg)
方差分析的基本思想是:当各类别总体均数相同时,
.jpg) 间的差异
间的差异.jpg)
由随机误差造成,
与的比值应接近1,当其比值大于1、并超出一定的范围时,可以认为各类别间的总体均数不全相等、存在差异。
3.6.2 统计量
(1)整体均数比较
对各类别均数整体方面的检验,统计量为:
.jpg)
由分子自由度为
.jpg) 、分母
、分母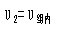 、显著水平a,查方差分析专用F界值表,得界值
、显著水平a,查方差分析专用F界值表,得界值.jpg) ,统计量F与界值
,统计量F与界值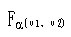
比较,若
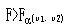 ,P<0.05,可以认为不同类别的总体均数不全相同,需进一步对两两间的情况进行检验,否则,P>0.05,认为各类总体均数相同。
,P<0.05,可以认为不同类别的总体均数不全相同,需进一步对两两间的情况进行检验,否则,P>0.05,认为各类总体均数相同。(2) 两两比较
市场研究中,多个样本均数间的两两比较(称为多重比较,multiple comparison),常采用q检验(Newman-Keuls method,SPSS中用S-N-K法),统计量为:
.jpg)
q界值除与显著水平a有关外,还与分子、分母自由度有关,分子自由度等于A类与B类间的类别数a与分母自由度为误差自由度
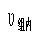 。分子自由度a的计算方法是,将每类样本均数按从小到大的顺序排列,a=A类的序号-B类的序号+1。
。分子自由度a的计算方法是,将每类样本均数按从小到大的顺序排列,a=A类的序号-B类的序号+1。3.6.3 实例
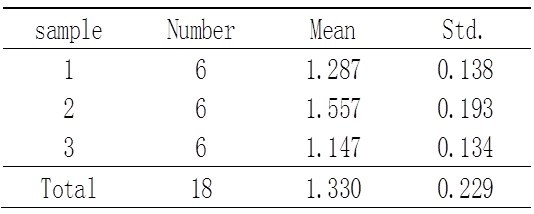
为评估某行业职工收入情况,调查三地该行业职工各6人,结果见下表。
表1 三地某行业18名职工年收入表(万元)

(1) 统计描述
(2) F检验

界值F0.05(2,15)=3.68,P<0.05,可以认为三地平均工资有差异。
(3) q检验
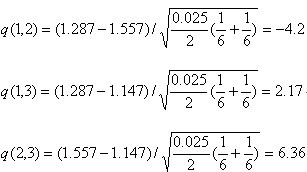
按均数大小排列,(1)类别3,(2)类别1,(3)类别2,所以,a(1,2)=2,a(1,3)=2,a(2,3)=3
显著水平取0.05,查q界值表, q0.05(2,15)=3.01, q0.05(3,15)=3.67,经比较,可以认为甲、丙地区间无差别,乙与甲、乙与丙间有差异。
上一篇下一篇




